
OpenAI recently announced a new feature for reinforcement fine-tuning that will become available in the OpenAI Playground. This announcement was made during the second day of their “12 Days of OpenAI” event. The feature will allow users to teach models to reason within specific domains, enabling custom-tuned models to deliver significantly better results in specialized tasks. Initially, this capability will be offered to a limited set of alpha users, with broader availability expected in Q1. Interested users can apply for access through an alpha sign-up form.
When this feature is introduced, users will gain access to a fine-tuning method selector in the UI. This selector will include three options in addition to the currently available supervised fine-tuning: direct reference optimization and reinforcement fine-tuning. It is anticipated that direct reference optimization may eventually be launched as a standalone feature with its own announcement.
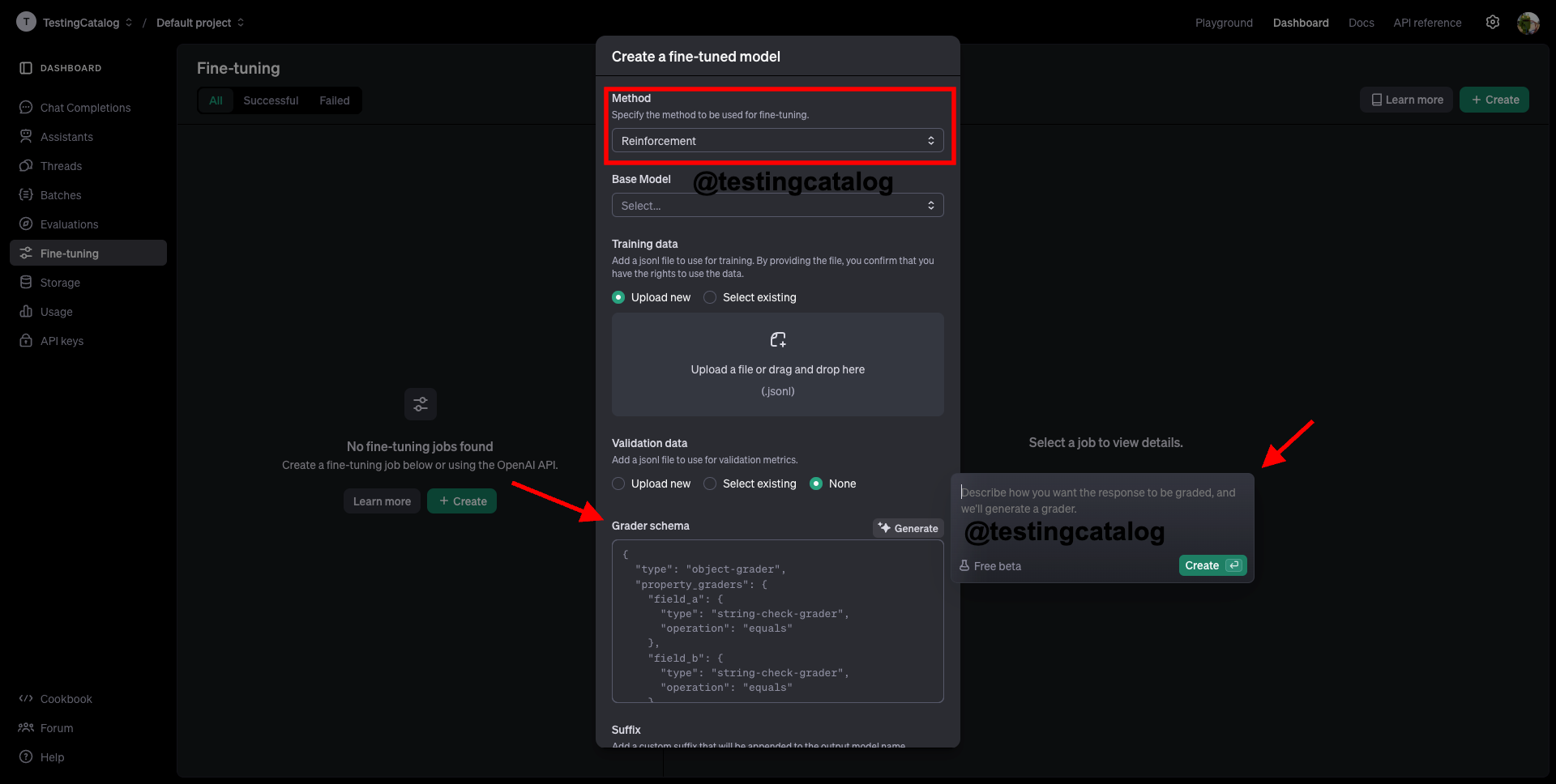
For reinforcement fine-tuning, users will have the ability to specify a grader schema to define how model responses should be evaluated. Alternatively, they can use a prompt to generate this schema automatically, making the process more intuitive and flexible.
I noticed during the "12 Days of OpenAI: Day 2" livestream today that the OpenAI Platform sidebar has a new icon, possibly related to one of the upcoming announcements - "Custom Voices"
— Tibor Blaho (@btibor91) December 6, 2024
- "Create a voice below or using the OpenAI API"
- "Create a voice sample of yourself by… pic.twitter.com/c6ZGZpHBwr
In addition to reinforcement fine-tuning, other features are also under development. One notable tool will allow users to clone their own voice. By reading a specific paragraph of text, users can enable OpenAI to create a voice clone capable of pronouncing any text in their own voice. This feature will likely be restricted to users aged 18 and older, marking a significant step in simplifying voice cloning technology.





