Today, OpenAI announced the upcoming availability of their much-anticipated voice mode Alpha. Initially planned for release to a small group of users at the end of June, the rollout has been delayed by a month and is now expected to start at the end of July. They also mentioned that all Plus users can expect access to the new voice mode in the Fall. Additionally, features like screen sharing and camera access will be released separately as they are developed.
We're sharing an update on the advanced Voice Mode we demoed during our Spring Update, which we remain very excited about:
— OpenAI (@OpenAI) June 25, 2024
We had planned to start rolling this out in alpha to a small group of ChatGPT Plus users in late June, but need one more month to reach our bar to launch.…
This announcement aligns with earlier assumptions about the development status of the voice mode. In May, reverse engineers determined that the product demo presented was not a live implementation, suggesting it could take months before the voice mode would be ready. Another assumption was that it would only be released when the macOS ChatGPT app was ready.
BREAKING: In case you wondering, the OpenAI demo was done through a special DEMO mode inside ChatGPT apps 🤖 https://t.co/dBByrgJ45V pic.twitter.com/Oaygn4vhzw
— TestingCatalog News 🗞 (@testingcatalog) May 15, 2024
Last week, a significant issue with image previews was resolved, and this week, OpenAI announced that the desktop app is now available to all users. Previously, it was limited to a select group.
The ChatGPT desktop app for macOS is now available for all users.
— OpenAI (@OpenAI) June 25, 2024
Get faster access to ChatGPT to chat about email, screenshots, and anything on your screen with the Option + Space shortcut: https://t.co/2rEx3PmMqg pic.twitter.com/x9sT8AnjDm
Now, anyone with macOS on an Apple Silicon laptop can download and install the desktop app. The app now includes an automatic correction feature similar to iOS, and a new UI with the voice mode Alpha, which is currently hidden behind a feature flag. Users can switch between standard and advanced voice modes, although the advanced mode is not yet fully functional, as confirmed by the latest announcement.
This delay has caused significant frustration among users, with many considering switching to Claude by Anthropic due to their recent advancements.
New model appeared in my ChatGPT models list. GPT4o (S2S) Anyone knows what is with this one? :P @apples_jimmy @alwaysaq00 @kimmonismus pic.twitter.com/NuEfVZVaI6
— Bøgðán Iønút (@ionu___) June 26, 2024
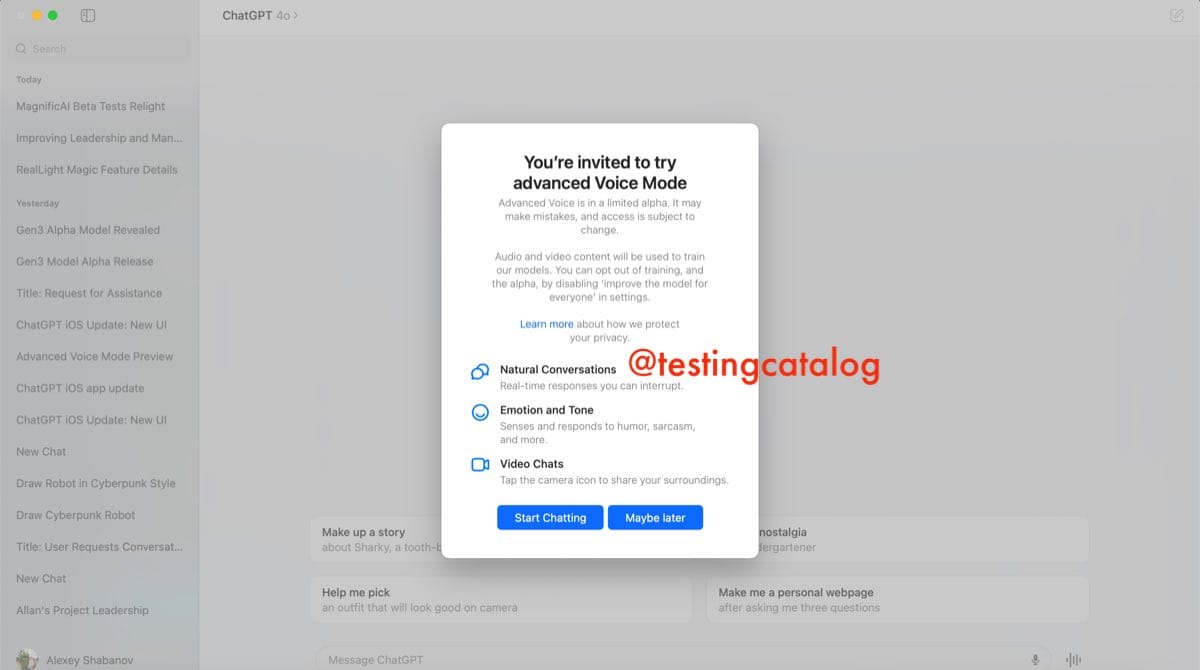
Later the next day, some users also saw the invitation screen for the alpha program on iOS and desktop apps. However, after pressing the start testing button, they encountered the current voice UI with the current voice model. It’s unclear if this was due to a configuration mistake. Some users reported seeing an alpha model called S2S, likely meaning speech-to-speech. These reports came mostly from Europe, suggesting that the S2S model is being deployed in the European region. Unfortunately, no one has been able to access the new voice model yet.





