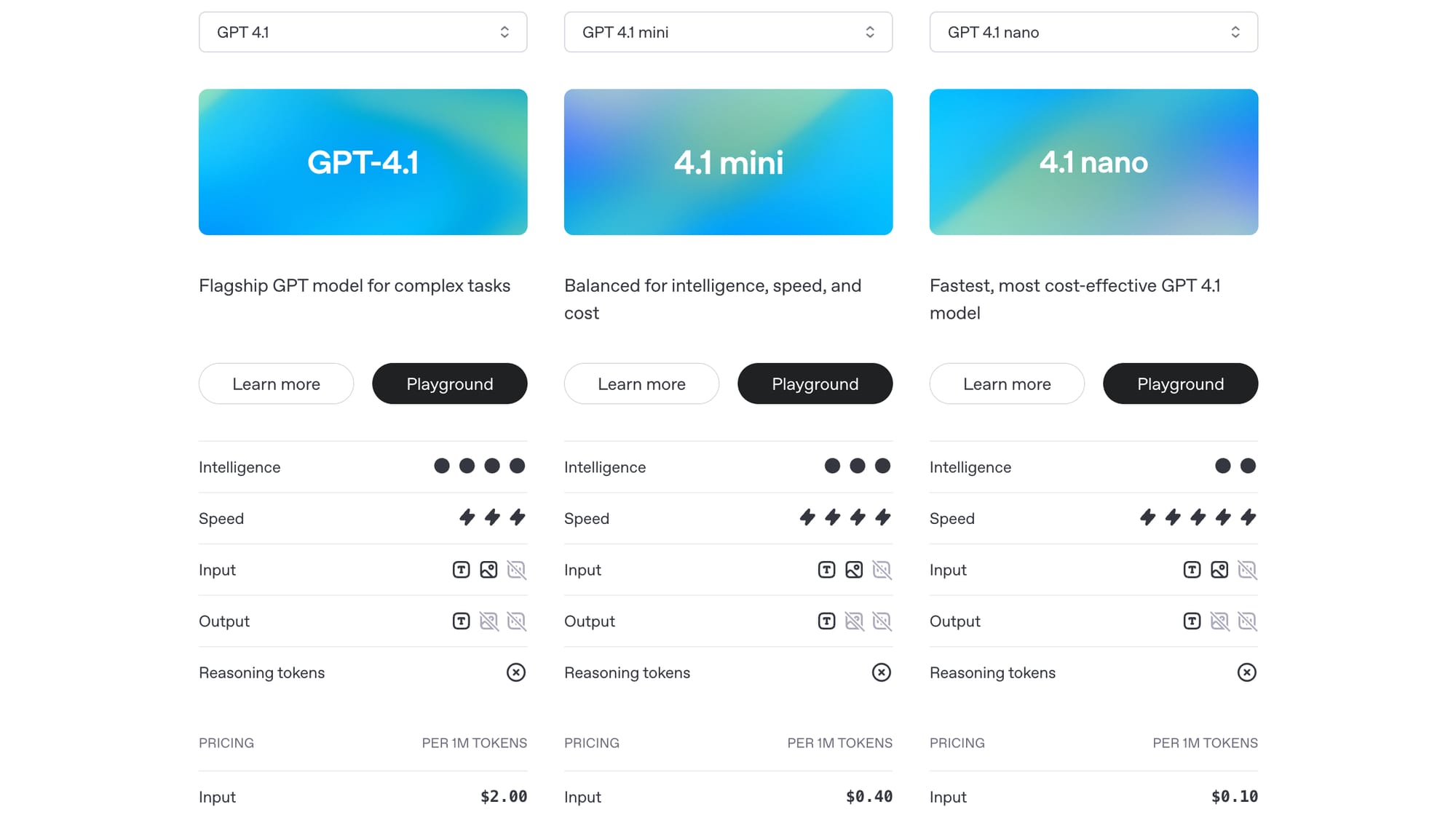
OpenAI has introduced three new models available through its API: GPT-4.1, GPT-4.1 mini, and GPT-4.1 nano. These models succeed the GPT-4o series, showing advances in coding capabilities, adherence to instructions, and processing extended context lengths up to 1 million tokens. They also feature updated knowledge through June 2024. Aimed at developers using the API, these models are available now. The company highlights that this release results from collaboration with the developer community to tune the models for practical tasks.
The GPT-4.1 family demonstrates superior results on various benchmarks compared to GPT-4o and GPT-4o mini. GPT-4.1 shows a significant jump on the SWE-bench Verified coding test (54.6%) and Scale’s MultiChallenge for instruction following (38.3%). All three models handle 1 million token context windows, enabling work with large codebases or documents. GPT-4.1 mini offers substantial performance, sometimes surpassing GPT-4o, but with reduced latency and cost. GPT-4.1 nano is presented as the quickest and most affordable option, suitable for tasks like classification, featuring the 1 million token context despite its small size. These capabilities also make the models suited for building agent systems.
For the next seven days, get free unlimited GPT-4.1 on Windsurf, on us.
— Windsurf (@windsurf_ai) April 14, 2025
That’s right, free.
We are very excited about GPT-4.1 given our internal evals. We have rate limits to prevent abuse, so go build without worrying about credits. pic.twitter.com/xBZS9UmUVb
While available via API, OpenAI notes that many underlying improvements are being integrated into the current GPT-4o version within ChatGPT. Concurrent with this launch, OpenAI announced the deprecation of the GPT-4.5 Preview model in the API, set for July 14, 2025, citing GPT-4.1's comparable or better utility at lower cost. Pricing for the new models is lower than GPT-4o, with GPT-4.1 being 26% less expensive for median queries and increased prompt caching discounts. Alpha testers like Qodo reported GPT-4.1 produced better code review suggestions in 55% of cases compared to other models, while Carlyle found it 50% better at data retrieval from large documents.





