
Character.AI has unveiled Avatar FX, a model that turns a single image into photoreal video whose face, hands, and body move in sync while the frame also delivers synced speech or song.
Posted on April 21, 2025, the release was echoed by tech press the following day, confirming the feature is live in the lab and headed for the main app.
📽️Say hello to AvatarFX — our cutting-edge video generation model. Cinematic. Expressive. Mind-blowing. Dive in: https://t.co/aF5zDrKLIK #CharacterAI #AvatarFX pic.twitter.com/Rkqo4SXEgX
— Character.AI (@character_ai) April 22, 2025
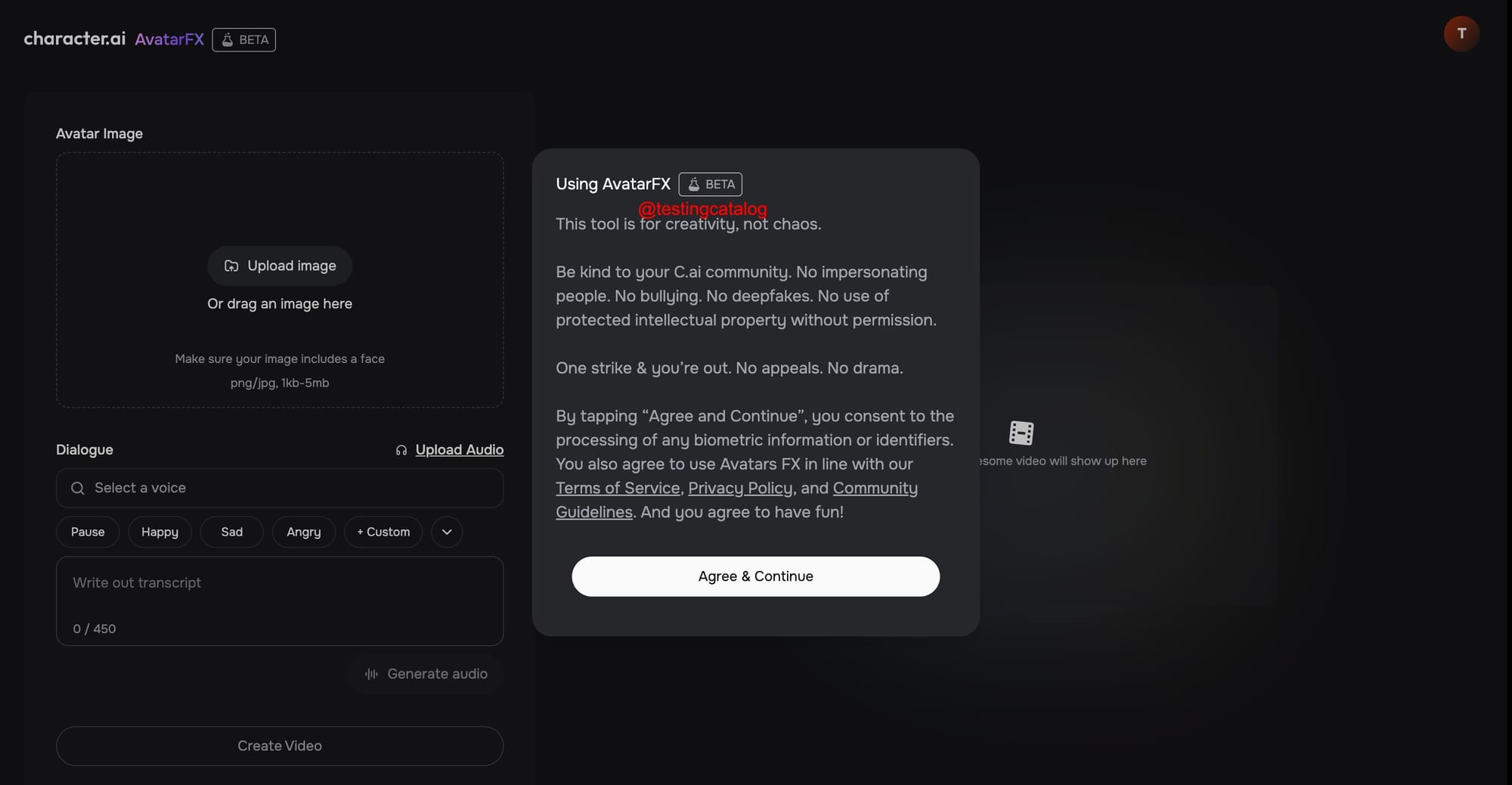
Avatar FX relies on a flow‑based diffusion transformer (DiT) pipeline and Character.AI’s proprietary TTS engine to generate motion that tracks the audio stream frame‑by‑frame. According to the team, it sustains long clips, handles dialogues with several speakers, and accepts a user‑supplied keyframe so creators can direct every scene instead of using pure text prompts.
CAI+ subscribers will be first in line, with broader access “over the coming months”; a public wait‑list is already live on both web and mobile.
Tom’s Guide notes that current leaders such as Pika, Runway Gen‑3, and Luma Dream Machine limit either clip length or resolution, trade‑offs Avatar FX is designed to avoid. Earlier coverage of avatar generators highlights uncanny motion drift—an issue Character.AI says its consistency pipeline mitigates.
The video push follows Google’s reported US $2.7 billion licensing‑and‑talent deal that folded Character.AI’s founders into the Gemini effort, giving the startup fresh resources for heavy compute. Financially, the company raised US $150 million in a 2023 Series A at a US $1 billion valuation, providing capital to scale new multimodal models.
Founded in 2021 by ex‑Google researchers Noam Shazeer and Daniel De Freitas, the Menlo Park firm now draws roughly 100 million monthly visits. Avatar FX shifts those text‑based personas into moving faces, furthering Character.AI’s goal of letting anyone craft longer‑form stories at the press of “Generate.”





