
Mistral AI has announced the release of Mistral Small 3, a 24-billion-parameter open-source language model optimized for low latency and high efficiency. Released under the Apache 2.0 license, this model is designed to perform competitively with much larger models, such as Llama 3.3 70B and Qwen 32B, while being over three times faster on equivalent hardware. Mistral Small 3 caters to the majority of generative AI tasks, including instruction following and conversational assistance, with a focus on rapid response times.
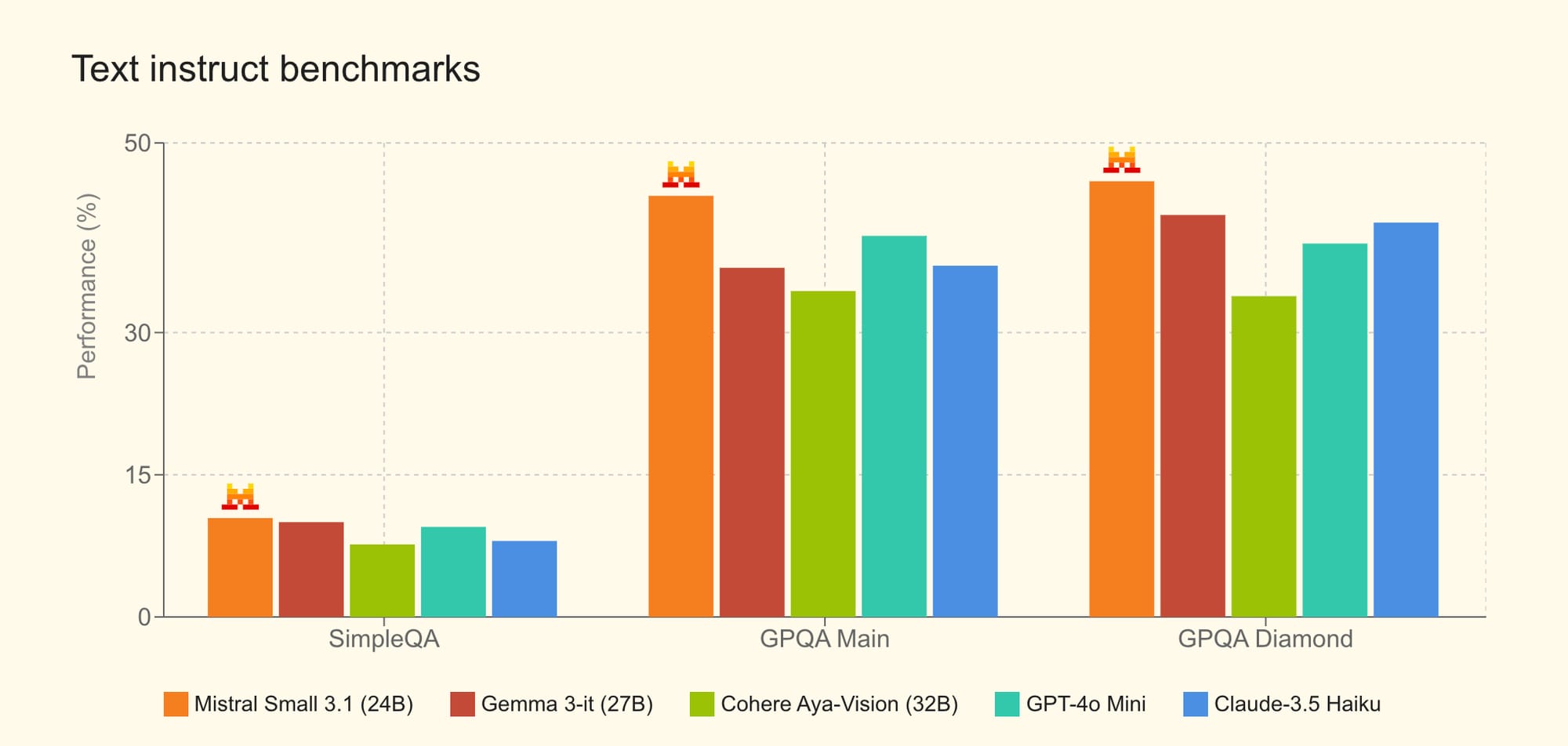
Introducing Mistral Small 3.1.
— Mistral AI (@MistralAI) March 17, 2025
Multimodal, Apache 2.0, outperforms Gemma 3 and GPT 4o-mini.https://t.co/BHLAAaKZ9w pic.twitter.com/DibHXaQDMm
The model achieves over 81% accuracy on the Massive Multitask Language Understanding (MMLU) benchmark and processes up to 150 tokens per second, making it one of the most efficient models in its size category. Mistral Small 3 is particularly well-suited for local deployment due to its reduced number of layers, which minimizes latency during inference. It can run on consumer-grade hardware such as an RTX 4090 GPU or a MacBook with 32GB of RAM when quantized.
The release includes both pre-trained and instruction-tuned checkpoints, providing flexibility for developers to fine-tune the model for domain-specific applications. Notably, the model was not trained using reinforcement learning or synthetic data, positioning it as an earlier-stage base model for building advanced reasoning capabilities.
Key use cases for Mistral Small 3 include:
- Fast-response virtual assistants
- Low-latency function execution in automated workflows
- Domain-specific fine-tuning for industries like healthcare and legal services
- Private local inference for organizations handling sensitive data
Industries already exploring its potential include financial services (e.g., fraud detection), healthcare (e.g., customer triaging), and robotics (e.g., command and control).
Mistral Small 3 is available on multiple platforms, including Hugging Face, Ollama, Kaggle, Together AI, Fireworks AI, and IBM Watson X. Future integrations are planned with NVIDIA NIM, Amazon SageMaker, Groq, Databricks, and Snowflake.
This release underscores Mistral AI's commitment to open-source development. The company has pledged to continue using the Apache 2.0 license for its general-purpose models while transitioning away from MRL-licensed offerings. This move aims to foster innovation by enabling developers to freely modify and deploy the models across various environments.





