
Hume AI has introduced "Octave," a groundbreaking text-to-speech (TTS) model that aims to revolutionize the way synthetic voices are generated by incorporating an understanding of context and emotional nuance.
Unlike traditional TTS systems, which primarily focus on converting text into speech with basic prosody, Octave is designed to interpret the meaning and emotional tone behind the text, producing speech that aligns more closely with human expression.
The model is particularly noteworthy for its ability to create dynamic voice outputs tailored to specific contexts, making it suitable for applications such as virtual assistants, accessibility tools, and creative content production. Octave also offers customizable voice and personality creation features, allowing developers and users to fine-tune the emotional delivery of speech.
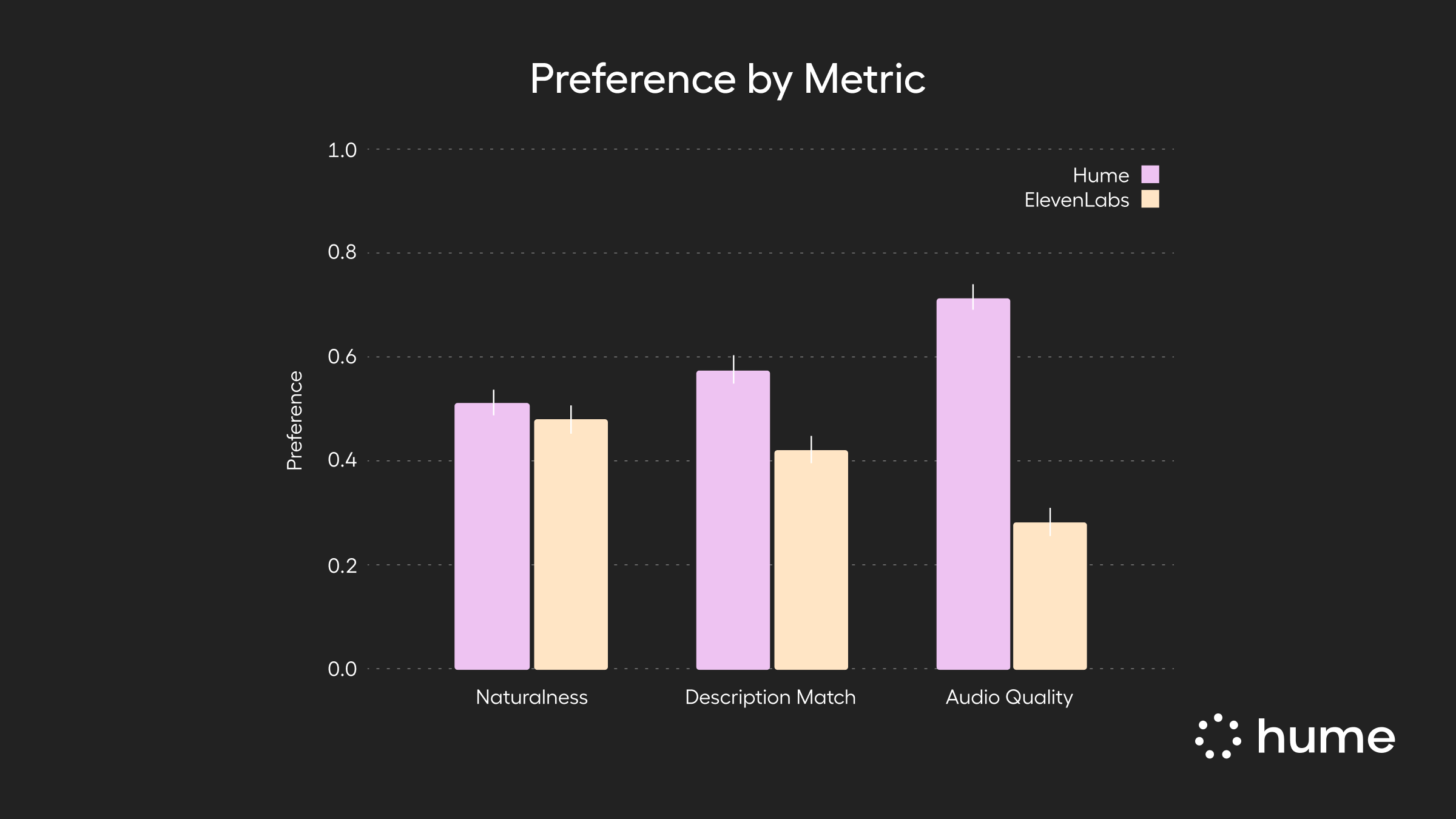
Hume AI's focus on emotional intelligence in machine learning sets Octave apart from other TTS solutions. By leveraging advanced natural language processing and speech synthesis techniques, the model aims to bridge the gap between mechanical voice outputs and authentic human communication. This innovation could have far-reaching implications for industries ranging from customer service to entertainment.
Today, we’re releasing Octave: the first LLM built for text-to-speech.
— Hume (@hume_ai) February 26, 2025
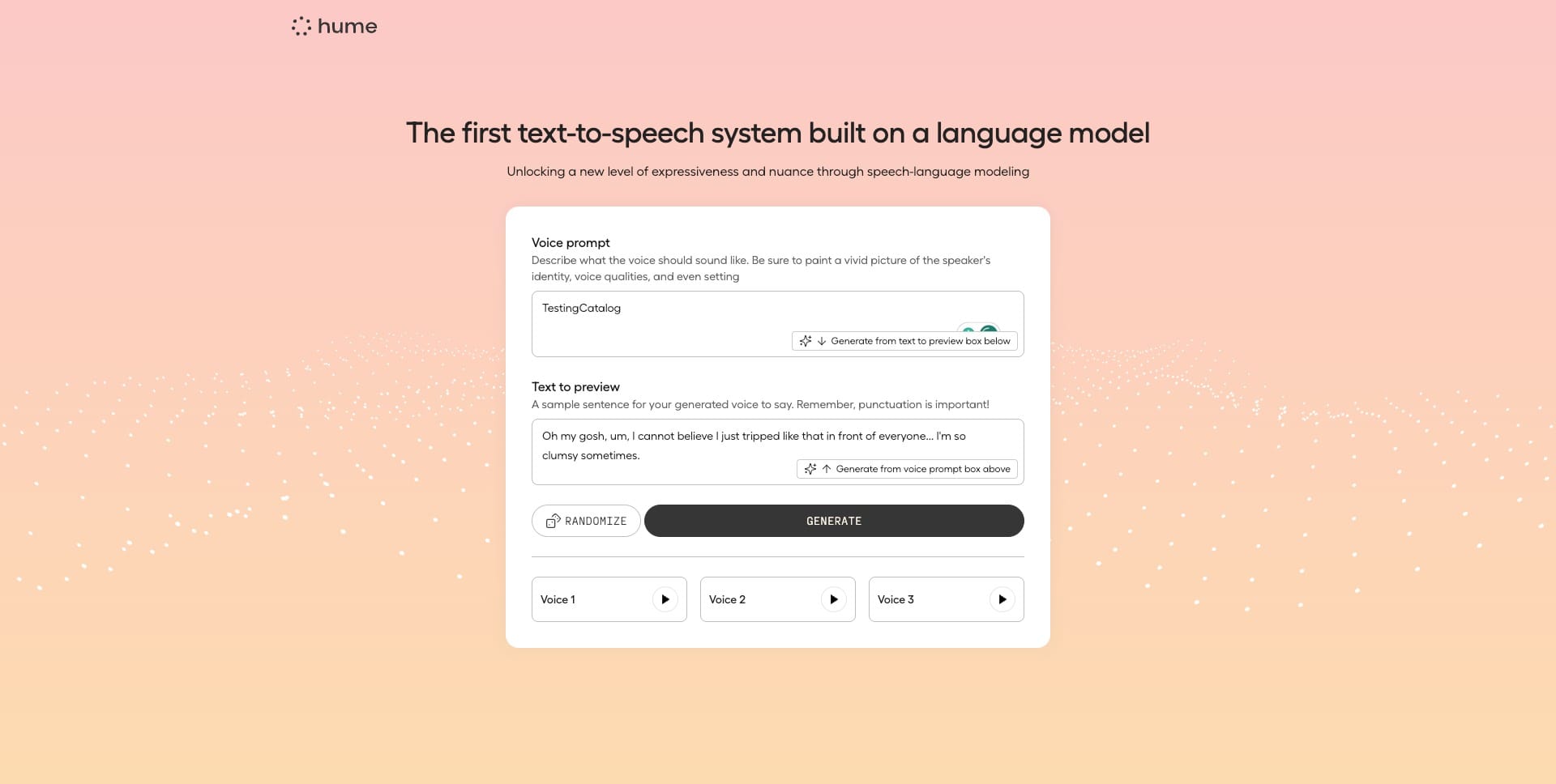
🎨Design any voice with a prompt
🎬 Give acting instructions to control emotion and delivery (sarcasm, whispering, etc.)
🛠️Produce long-form content on our Creator Studio
Unlike traditional TTS that just… pic.twitter.com/Fag70tJrod
The release date for Octave is February 26, 2025. The model's emphasis on emotional context positions it as a significant advancement in TTS technology. Industry reactions suggest that Octave could set a new standard for voice AI systems by combining technical sophistication with practical versatility.





